简介 Link to heading
PyTorch 2.0 的使命是更快、更 Pythonic 以及一如既往地支持动态特性。为了达到这个目的,PyTorch 2.0 引入了 torch.compile,在解决 PyTorch 固有的性能问题的同时,把部分用 C++ 实现的东西引入 Python 中。PyTorch 2.0 利用了 4 个组件: TorchDynamo,AOTAutograd,PrimTorch 和 TorchInductor。本文以几个简单的案例讲解 TorchDynamo 的使用方法和实现原理。
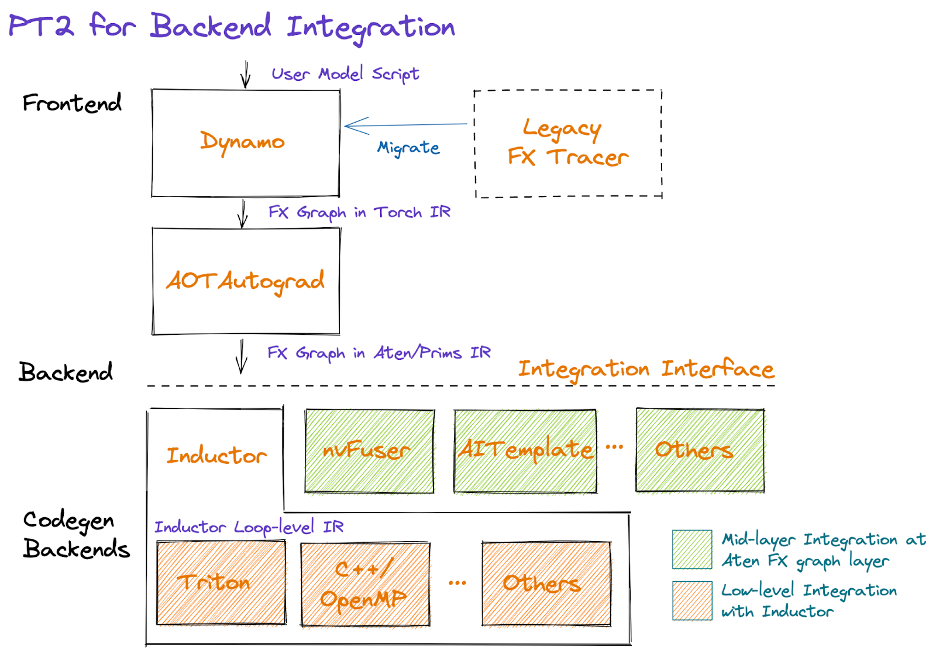
TorchDynamo 的作用是从 PyTorch 应用中抓取计算图,相比于 TorchScript 和 TorchFX,TorchDynamo 更加灵活、可靠性更高。用过 TorchScript 的朋友知道,通过 jit.trace 或者 jit.script 把模型转化为 TorchScript 的过程困难重重,往往需要修改大量源代码。而 TorchFX 在捕获计算图时,遇到不支持的算子会直接报错,最常见的就是 if 语句。TorchDynamo 克服了 TorchScript 和 TorchFX 的缺点,使用起来极为方便,用户体验相比于 TorchScript 和 TorchFX 大幅提升。配合 TorchInductor 等后端编译器,经 TorchDynamo 捕获的计算图只需要几行代码的改动就可以观测到不错的性能提升。
用法 Link to heading
使用 TorchDynamo 的方法非常简单,可以通过 torch.compile() 或者 torch._dynamo.optimize(),其中可以指定 backend 为 'inductor'、'eager',或者以用户自定义的 Python 函数作为 graph compiler。在下面的代码片段中,我们以自定义的 Python 函数 my_compiler 作为编译器:
from typing import List
import torch
def my_compiler(gm: torch.fx.GraphModule, example_inputs: List[torch.Tensor]):
print(">>> my_compiler() invoked:")
print(">>> FX graph:")
gm.graph.print_tabular()
print(f">>> Code:\n{gm.code}")
return gm.forward # return a python callable
@torch.compile(backend=my_compiler)
def foo(x, y):
return (x + y) * x
if __name__ == "__main__":
a, b = torch.randn(10), torch.ones(10)
foo(a, b)
执行上面的代码,可以看到 TorchDynamo 把从函数 foo() 中捕获到一张计算图,TorchDynamo 以 FX Graph 保存捕获到的计算图:
>>> FX graph:
opcode name target args kwargs
------------- ------ ----------------------- --------- --------
placeholder x x () {}
placeholder y y () {}
call_function add <built-in function add> (x, y) {}
call_function mul <built-in function mul> (add, x) {}
output output output ((mul,),) {}
>>> Code:
def forward(self, x : torch.Tensor, y : torch.Tensor):
add = x + y; y = None
mul = add * x; add = x = None
return (mul,)
Python 字节码 Link to heading
TorchDynamo 捕获计算图是在翻译 Python 字节码的过程中实现的。Python 函数在执行前会被 Python 虚拟机编译为字节码 (bytecode),每一个 Python 函数的实例都对应一个 frame,其中保存着运行该函数所需要的全局变量、局部变量、字节码等等。
为了便于理解 Python 虚拟机、字节码和 TorchDynamo 的行为,下面用 hello() 函数简要介绍下 Python 字节码的行为。我们可以用 dis 包查看 Python 函数的字节码:
import dis
def hello():
print("Hello, world!")
for k in ["co_names", "co_varnames", "co_consts"]:
print(k, getattr(hello.__code__, k))
print(dis.dis(hello))
执行上面的代码,我们得到下面的结果:
co_names ('print',)
co_varnames ()
co_consts (None, 'Hello, world!')
0 LOAD_GLOBAL 0 (print)
2 LOAD_CONST 1 ('Hello, world!')
4 CALL_FUNCTION 1
6 POP_TOP
8 LOAD_CONST 0 (None)
10 RETURN_VALUE
其中包含了 6 条 Python 字节码,它们的功能如下:
LOAD_GLOBAL 0: 从f_builtins和f_globals中加载由下标 0 所引用的全局对象,把它压到数据栈上;LOAD_CONST 1: 从co_consts中加载由下标 1 所引用的常量,把它压到数据栈上;CALL_FUNCTION 1: 从栈顶出栈 1 个元素作为函数参数,再出栈一个元素作为被调函数,调用该函数并把返回值压到数据栈上;POP_TOP: 从栈顶移除一个元素;LOAD_CONST 0: 从co_consts中加载由下标 0 所引用的常量,把它压到数据栈上;RETURN_VALUE: 从栈顶出栈 1 个元素,把它作为返回值返回给主调函数;
Python 虚拟机是 Stack Machine,它维护了 3 个 stack:
- Call Stack: 其中的条目是 Python frame,类似 C 的函数调用栈;
- Evaluation Stack (or Data Stack): 每个 Python frame 都有一个 evaluation stack,执行 Python 字节码时的数据由该 stack 管理,这与常见的 Register Machine 有所区别;
- Block Stack: 每个 Python frame 都有一个 block stack,目的是跟踪 Python 中的控制结构,例如循环、
try / except、with语句等,进入/退出这类控制结构时会有对应的条目被 push/pop。Block stack 帮助 Python 在任意时刻都知道当前活跃的 block,continue和break会影响当前活跃的 block;
更多 Python 字节码和虚拟机的细节可以参考 _PyEval_EvalFrameDefault。
实现原理 Link to heading
TorchDynamo 的 编译过程发生在将要执行前,它是一个 JIT 编译器。在 Python 将要执行函数时,TorchDynamo 开始翻译字节码并捕获计算图。在 Python 虚拟机 (PVM) 中有一个非常重要的函数 _PyEval_EvalFrameDefault,它的功能是在 PVM 中逐条执行编译好的字节码。TorchDynamo 的入口是 PEP-523 提供的 CPython Frame Evaluation API,它可以让用户通过 回调函数(callback function) 获取字节码,并把修改过后的字节码返回给解释器执行,或者执行预先编译好的目标代码,从而可以在 Python 中实现 即时编译器 (JIT Compiler) 的功能。TorchDynamo 正是通过 PEP-523 把 TorchDynamo 的核心逻辑引入到 Python 虚拟机中,从而在函数将要运行前获取字节码。
下图展示了 TorchDynamo 的核心原理:
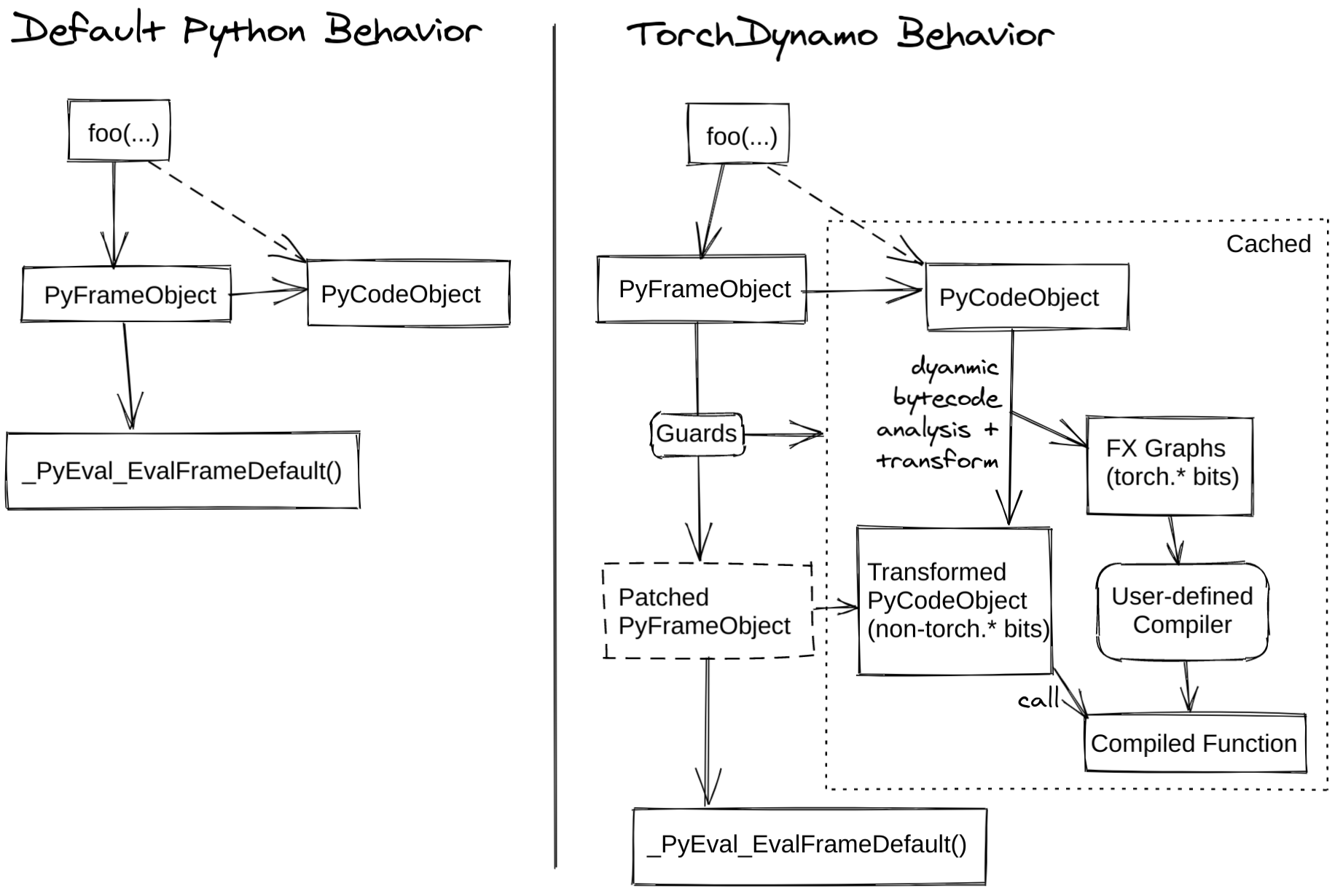
TorchDynamo 实现了一个 Python 虚拟机的模拟器,在模拟 Python 字节码执行的过程中构建出对应的计算图。仍以 foo() 为例:
@torch.compile(backend=my_compiler)
def foo(x, y):
return (x + y) * x
foo() 对应的字节码如下,TorchDynamo 在翻译字节码 BINARY_ADD 和 BINARY_MULTIPLY 时在 FX Graph 中建立了 operator.add 和 operator.mul 两个 FX Node,最后形成一张完整的计算图:
0 LOAD_FAST 0 (x)
2 LOAD_FAST 1 (y)
4 BINARY_ADD
6 LOAD_FAST 0 (x)
8 BINARY_MULTIPLY
10 RETURN_VALUE
为了检验 TorchDynamo 捕获的计算图在下次执行时还是否有效,TorchDynamo 会为被编译的函数创建 Guard。从 Guard 生成的 Python 可执行函数 check_fn,在 TorchDynamo 中 负责检测被编译函数的输入属性是否发生变化,如果没有发生变化则可以重用此前编译好的函数,否则当前输入对此前编译好的函数无效,需要 重新编译 (graph recompilation) 该函数。TENSOR_MATCH 是检测张量信息的 Guard,在默认情况下,主要负责检查输入的张量 device、shape、stride 等属性是否改变。
foo() 函数对应的 check_fn 如下,它会调用 C++ 函数检查张量 x 和 y 的信息是否发生变化,进而决定是否能重用此前编译好的函数:
GUARDS ___guarded_code.valid and ___check_tensors(x, y)
经 TorchDynamo 编译好的函数被保存在 frame 的 cache 中,从而避免再次编译相同的函数和输入。默认情况下 cache 大小为 64,也就是说,对于同一个 Python 函数,它的输入最多可以有 64 种变化,超过这个限制后 TorchDynamo 不再编译该函数。
Graph Break Link to heading
TorchDynamo 并不能把所有的函数都捕获到一张计算图中。TorchDynamo 碰到无法支持的算子时会创建 graph break,把计算图切分成它可以支持的几张子图,并返回 Python 解释器执行它无法处理的算子。最常见的导致 graph break 的案例是用张量的值作为 if 语句的条件,以下面的函数为例:
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
if b.sum() < 0:
b = b * -1
return x * b
TorchDynamo 会把 toy_example() 拆分为 3 张子图,不能处理的 if 语句由 Python 解释器执行。编译后对应的 Python 函数如下,执行完编译好的子图 __compiled_fn_0() 后,程序返回到 Python 解释器,根据 if 语句的结果选择执行还未编译的子图 __resume_at_30_1() 或 __resume_at_38_2():
def compiled_toy_example(a, b):
x, lt = __compiled_fn_0(a, b)
if lt:
return __resume_at_30_1(b, x)
else:
return __resume_at_38_2(b, x)
其中包含了 3 个函数:
__compiled_fn_0(): TorchDynamo 编译好的子图,对应if语句前面的部分:def __compiled_fn_0(a, b): x = a / (torch.abs(a) + 1) return b.sum() < 0:__resume_at_30_1(): TorchDynamo 未编译的子图,对应if分支 (TorchDynamo 直接操纵字节码,为了方便解释这里用了 Python 伪代码,并假设 Python 中支持 goto 和 label):# pseudo python code with goto and label def __resume_at_30_1(b, x): goto if_next x = a / (torch.abs(a) + 1) if b.sum() < 0: label if_next b = b * -1 return x * b该函数会在首次执行时被 TorchDynamo 捕获并编译。
__resume_at_38_2(): TorchDynamo 未编译的子图,对应else分支,该函数也会在首次执行时被 TorchDynamo 捕获并编译:# pseudo python code with goto and label def __resume_at_38_2(b, x): goto if_jump x = a / (torch.abs(a) + 1) if b.sum() < 0: b = b * -1 label if_jump return x * b
Dynamic Shape Link to heading
默认情况下 TorchDynamo 为 static shape 模式,捕获计算图时张量的 shape 和 stride 被特化并记录在 Guard 中。捕获计算图结束时会生成 Guard 对应的 check_fn,用于 检查该计算图中的输入信息有没有发生变化。如果没有发生变化则重用已经编译好的计算图,否则重新捕获并编译计算图 (graph recompilation)。当设置环境变量 TORCHDYNAMO_DYNAMIC_SHAPES 为 1 时,此时 TorchDynamo 以 dynamic shape 模式捕获计算图,张量的 shape 和 stride 不会被特化、不会被记录在 Guard 中,生成的 check_fn 也不检查 shape 和 stride。因此,以不同 shape 或 stride 的张量执行编译好的计算图时,不会重新捕获计算图和重新编译。
下面的代码片段中,test() 调用了两次 toy_example(),两次不同的调用之间 tensor 的 shape 不同,所以会触发重新编译:
@torch.compile(backend=my_compiler)
def toy_example(x):
x = x / (torch.abs(x) + 1)
return x
def test():
x = torch.randn(10)
toy_example(x)
x = torch.randn(20)
toy_example(x)
使用 torch.compile() 编译 toy_example() 并运行,可以看到这里触发了两次 toy_example() 的编译。这是因为第二次调用 toy_example() 时,张量 x 没能通过 Guard 检查。
相关函数调用栈:
- [C011] > torch/csrc/dynamo/guards.cpp#L49 [New]
- [C010] > torch/csrc/dynamo/guards.cpp#L207 [New]
- [P009] > <string>#L2:<lambda>
- [C008] > torch/csrc/dynamo/eval_frame.c#L355
- [C007] > torch/csrc/dynamo/eval_frame.c#L621
- [C006] > torch/csrc/dynamo/eval_frame.c#L346
- [C005] > torch/csrc/dynamo/eval_frame.c#L505
- [C004] > torch/csrc/dynamo/eval_frame.c#L640
- [C003] > torch/csrc/dynamo/eval_frame.c#L621
- [C002] > torch/csrc/dynamo/eval_frame.c#L346
- [P001] > torch/_dynamo/eval_frame.py#L233
- [P000] > test.py#L18:test [New]
循环展开 Link to heading
TorchDynamo 把 Python 中的循环捕获为循环展开的计算图,即捕获的计算图中不再包含循环。例如下面的代码片段,其中的 for 循环迭代了 4 次、每次执行一次乘法操作:
@torch.compile
def toy_example(x, n):
for i in range(1, n+1):
x = x * i
return x
def test():
x = torch.randn(10)
toy_example(x, 4)
捕获到的计算图对应的 Python 函数为:
def forward(self, x : torch.Tensor):
mul = x * 1; x = None
mul_1 = mul * 2; mul = None
mul_2 = mul_1 * 3; mul_1 = None
mul_3 = mul_2 * 4; mul_2 = None
return (mul_3,)
这个过程的原理是 TorchDynamo 在它的 Python 虚拟机模拟器中模拟运行了 FOR_ITER 这条字节码指令,然后捕获在每次迭代中出现的运算,而不是把 for 循环本身捕获到计算图中。
这个过程的函数调用栈如下:
- [P053] > torch/_dynamo/symbolic_convert.py#L911 [New]
- [P049] > torch/_dynamo/symbolic_convert.py#L537
- [P045] > torch/_dynamo/symbolic_convert.py#L590 [New]
- [P041] > torch/_dynamo/symbolic_convert.py#L1838 [New]
- [P037] > torch/_dynamo/convert_frame.py#L298 [New]
- [P033] > torch/_dynamo/bytecode_transformation.py#L488 [New]
- [P029] > torch/_dynamo/convert_frame.py#L279 [New]
- [P025] > torch/_dynamo/utils.py#L158 [New]
- [P021] > torch/_dynamo/convert_frame.py#L200 [New]
- [P017] > torch/_dynamo/convert_frame.py#L96 [New]
- [P013] > torch/_dynamo/convert_frame.py#L403 [New]
- [P009] > torch/_dynamo/eval_frame.py#L362
- [C008] > torch/csrc/dynamo/eval_frame.c#L355
- [C007] > torch/csrc/dynamo/eval_frame.c#L621
- [C006] > torch/csrc/dynamo/eval_frame.c#L346
- [C005] > torch/csrc/dynamo/eval_frame.c#L399
- [C004] > torch/csrc/dynamo/eval_frame.c#L640
- [C003] > torch/csrc/dynamo/eval_frame.c#L621
- [C002] > torch/csrc/dynamo/eval_frame.c#L346
- [P001] > torch/_dynamo/eval_frame.py#L233 [New]
- [P000] > test.py#L19:test [New]
内联函数 Link to heading
针对用户函数调用,TorchDynamo 会尝试内联 (inline) 被调函数,从而生成更大的计算图。但如果被掉函数中存在 graph break,那么内联就会失败,此时函数调用栈中的每个函数都会产生一个 graph break。
下面的代码片段中 test() 调用了递归函数 toy_example():
@torch.compile
def toy_example(x, n):
if n > 0:
return toy_example(x, n-1) * n
else:
return x
def test():
x = torch.randn(10)
toy_example(x, 4)
TorchDynamo 在捕获 toy_example(x, 4) 的计算图时,会尝试内联 toy_example(x, 3) 的计算图,依次类推,直到成功内联 toy_example(x, 0) 的计算图。最终生成一个大的计算图,其中的函数调用被展开:
def forward(self, x : torch.Tensor):
mul = x * 1; x = None
mul_1 = mul * 2; mul = None
mul_2 = mul_1 * 3; mul_1 = None
mul_3 = mul_2 * 4; mul_2 = None
return (mul_3,)
但在下面的代码片段中,用户函数 baz() 无法被 TorchDynamo 内联,因为其中的 if 条件依赖于张量的值,只有在运行时才能确定执行哪个分支,故而存在一个 graph break。这个 graph break 导致其调用者 bar() 和 foo 都产生了 graph break,最后总共生成 7 个计算图,baz() 中包含 3 个:
def baz(x):
return -x if x > 0 else x - 1
def bar(x):
return x * baz(x - 1)
@torch.compile
def foo(x):
return x * bar(2 * x)
def test():
x = torch.tensor([4])
foo(x)
TorchDynamo 通过字节码指令 CALL_FUNCTION 实现内联函数,其中识别用户函数调用并尝试内联,内联失败时恢复主调函数的状态并创建 graph break,子图编译完后返回解释器执行子函数调用。
这个过程通过 InliningInstructionTranslator 实现,它不支持子图编译,函数调用栈如下:
- [P034] > torch/_dynamo/exc.py#L69 [New]
- [P033] > torch/_dynamo/symbolic_convert.py#L234 [New]
- [P032] > torch/_dynamo/symbolic_convert.py#L537
- [P031] > torch/_dynamo/symbolic_convert.py#L590
- [P030] > torch/_dynamo/symbolic_convert.py#L1956
- [P029] > torch/_dynamo/symbolic_convert.py#L1930
- [P028] > torch/_dynamo/symbolic_convert.py#L524
- [P027] > torch/_dynamo/variables/functions.py#L90
- [P026] > torch/_dynamo/variables/functions.py#L251
- [P025] > torch/_dynamo/symbolic_convert.py#L469
- [P024] > torch/_dynamo/symbolic_convert.py#L988
- [P023] > torch/_dynamo/symbolic_convert.py#L341
- [P022] > torch/_dynamo/symbolic_convert.py#L537
- [P021] > torch/_dynamo/symbolic_convert.py#L590
- [P020] > torch/_dynamo/symbolic_convert.py#L1956 [New]
- [P019] > torch/_dynamo/symbolic_convert.py#L1930 [New]
- [P018] > torch/_dynamo/symbolic_convert.py#L524 [New]
- [P017] > torch/_dynamo/variables/functions.py#L90 [New]
- [P016] > torch/_dynamo/variables/functions.py#L251 [New]
- [P015] > torch/_dynamo/symbolic_convert.py#L469 [New]
- [P014] > torch/_dynamo/symbolic_convert.py#L988 [New]
- [P013] > torch/_dynamo/symbolic_convert.py#L341 [New]
- [P012] > torch/_dynamo/symbolic_convert.py#L537
- [P011] > torch/_dynamo/symbolic_convert.py#L590 [New]
- [P010] > torch/_dynamo/symbolic_convert.py#L1838 [New]
- [P009] > torch/_dynamo/convert_frame.py#L298 [New]
- [P008] > torch/_dynamo/bytecode_transformation.py#L488 [New]
- [P007] > torch/_dynamo/convert_frame.py#L279 [New]
- [P006] > torch/_dynamo/utils.py#L158 [New]
- [P005] > torch/_dynamo/convert_frame.py#L200 [New]
- [P004] > torch/_dynamo/convert_frame.py#L96 [New]
- [P003] > torch/_dynamo/convert_frame.py#L403 [New]
- [P002] > torch/_dynamo/eval_frame.py#L362
- [P001] > torch/_dynamo/eval_frame.py#L233 [New]
- [P000] > test.py#L24:test [New]
DistributedDataParallel Link to heading
通过数据并行在多 GPU 上训练深度学习模型时,需要调用 allreduce 对所有 GPU 上的梯度进行规约。深度学习框架中往往都把一些参数的梯度放在一个 bucket 中,当这个 bucket 中的所有梯度都已经就绪后,就会使用 allreduce 进行梯度规约。
TorchDynamo 捕获的计算图并不包含 DDP 的 hook 或者 allreduce 节点,如果整个模型被捕获为一张计算图,那么所有的 allreduce 都只能等到反向传播结束才能被触发,导致 allreduce 无法和反向传播 overlap。为了能够在一个 bucket 中的梯度就绪时及时调用 allreduce 进行通信,TorchDynamo 会在每个 bucket 的边界引入 graph break。
下面的代码片段中初始化了 EfficientNet-B0,它包含 5288548 个参数。为了便于展示,这里我们指定 DDP 中每个 bucket 的大小为 4 MB,因此梯度被分为 5 个 bucket。
#!/usr/bin/env python
# Run with: torchrun --nnodes=1 --nproc_per_node=1 test.py
import os
import torch
import torch.distributed as dist
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def run_epoch(model, loss_fn, optimizer, inputs, labels):
for i in range(3):
print(f">>> Iteration {i}")
outputs = model(inputs)
loss_fn(outputs, labels).backward()
optimizer.step()
def demo_basic():
dist.init_process_group("nccl")
rank = dist.get_rank()
print(f"Start running basic DDP example on rank {rank}.")
# create model and move it to GPU with id rank
device_id = rank % torch.cuda.device_count()
efficientnet = torch.hub.load(
"NVIDIA/DeepLearningExamples:torchhub",
"nvidia_efficientnet_b0",
pretrained=False,
)
model = efficientnet.to(device_id, memory_format=torch.channels_last)
model = DDP(model, device_ids=[device_id], bucket_cap_mb=4)
loss_fn = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
optimizer.zero_grad()
inputs = torch.randn((4, 3, 224, 224), device="cuda")
inputs = inputs.to(memory_format=torch.channels_last)
labels = torch.randn(4, 1000).to(device_id)
num_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f">>> Parameters: {num_params}")
model = torch.compile(model, backend="eager")
run_epoch(model, loss_fn, optimizer, inputs, labels)
if __name__ == "__main__":
demo_basic()
TorchDynamo 把上面的 EfficientNet-B0 捕获为 5 张计算图:
graph():
%x : torch.Tensor [#users=1] = placeholder[target=x]
%submod_0 : [#users=1] = call_module[target=compiled_submod_0](args = (%x,), kwargs = {})
%submod_1 : [#users=1] = call_module[target=compiled_submod_1](args = (%submod_0,), kwargs = {})
%submod_2 : [#users=1] = call_module[target=compiled_submod_2](args = (%submod_1,), kwargs = {})
%submod_3 : [#users=1] = call_module[target=compiled_submod_3](args = (%submod_2,), kwargs = {})
%submod_4 : [#users=1] = call_module[target=compiled_submod_4](args = (%submod_3,), kwargs = {})
return (submod_4,)
这个过程通过 DDPOptimizer 实现,函数调用栈如下:
- [P023] > torch/_dynamo/backends/distributed.py#L143 [New]
- [P022] > torch/_dynamo/output_graph.py#L644 [New]
- [P021] > torch/_dynamo/utils.py#L158
- [P020] > torch/_dynamo/output_graph.py#L583 [New]
- [P019] > torch/_dynamo/output_graph.py#L467 [New]
- [P018] > torch/_dynamo/symbolic_convert.py#L1910 [New]
- [P017] > torch/_dynamo/symbolic_convert.py#L537
- [P016] > torch/_dynamo/symbolic_convert.py#L590 [New]
- [P015] > torch/_dynamo/symbolic_convert.py#L1838 [New]
- [P014] > torch/_dynamo/convert_frame.py#L298 [New]
- [P013] > torch/_dynamo/bytecode_transformation.py#L488 [New]
- [P012] > torch/_dynamo/convert_frame.py#L279 [New]
- [P011] > torch/_dynamo/utils.py#L158 [New]
- [P010] > torch/_dynamo/convert_frame.py#L200 [New]
- [P009] > torch/_dynamo/convert_frame.py#L96 [New]
- [P008] > torch/_dynamo/convert_frame.py#L403 [New]
- [P007] > torch/_dynamo/eval_frame.py#L362
- [P006] > torch/nn/modules/module.py#L1526
- [P005] > torch/nn/parallel/distributed.py#L1082 [New]
- [P004] > torch/nn/parallel/distributed.py#L1096 [New]
- [P003] > torch/nn/modules/module.py#L1526 [New]
- [P002] > torch/_dynamo/eval_frame.py#L233 [New]
- [P001] > torch/_dynamo/eval_frame.py#L117 [New]
- [P000] > test.py#L13:run_epoch [New]
调试 Link to heading
当你在使用 TorchDynamo 的过程中碰到问题时,下面的代码片段可以打印日志以辅助调试:
import os
import logging
import torch._dynamo
torch._dynamo.config.log_level = logging.DEBUG
torch._dynamo.config.verbose = True
torch._dynamo.config.output_code = True
os.environ["TORCHDYNAMO_PRINT_GUARDS"] = "1"
除此之外,你还可以使用 eager backend 来检验 TorchDynamo 中的问题:
model = torch.compile(model, backend="eager")
如果你想知道捕获的计算图中哪些代码导致了 graph break,可以使用 dynamo.explain:
import torch
import torch._dynamo as dynamo
def toy_example(a, b):
x = a / (torch.abs(a) + 1)
print("woo")
if b.sum() < 0:
b = b * -1
return x * b
explanation, out_guards, graphs, ops_per_graph = dynamo.explain(
toy_example, torch.randn(10), torch.randn(10))
总结 Link to heading
- TorchDynamo 的作用是从 PyTorch 程序中捕获计算图;
- TorchDynamo 是一个 JIT compiler,它的工作原理是通过 PEP-523 获取将要执行的 Python 函数的字节码,在翻译字节码的过程中构建 FX Graph;
- 每个编译过的 frame 都有一个 cache,为同一个函数编译的不同输入属性的函数都保存在 cache 中;
- Guard 用来判断是否能够重用已经编译好的函数,它负责检查输入数据的属性有没有发生变化;
- 碰到不支持的算子时,TorchDynamo 会通过 graph break 把计算图切分为子图,不支持的算子由 Python 解释器执行;
- 循环在 TorchDynamo 捕获计算图时被展开;
- TorchDynamo 会试着内联被调函数,如果成功则生成一张大的计算图,失败则在主调函数中创建 graph break;
- TorchDynamo 会在 DDP bucket 的边界引入 graph break,从而确保 allreduce 能与反向传播同时执行;